Semantic Point Detector
ACM Multimedia 2011 的文章。
Motivation
这篇文章的动机在于 local features (Feature point Detection + Feature Description)其实是图像内容的一种表示方式,在深度学习兴起之前的主流范式就是 SIFT 这些特征点检测器 + Bag of Visual Worlds 对局部特征编码 + SVM 分类。但是当前的 interest point detector 主要是为了图像匹配设计的,选取这些特征点的出发点是 invariant under a certain family of transformations,让 the correspondence establishment between images with the same object or scene 足够的robust,而非是针对描述图像内容、揭示语义信息来最优设计的。
这篇文章的 Motivation 就在于 propose a learning-based point detector called semantic point detector which aims to select a set of points that can better represent the image. 通俗地讲,就是 SIFT 这些特征点,会检测出图像中所有的特征点,包括我们不希望被检测出的背景或者其他类别中的特征点,而这篇文章的 semantic point detector 就是希望学习出一个仅会检测感兴趣类别物体上的兴趣点的兴趣点检测器。具体的效果如下图所示,第一排是传统检测子检测出的特征点,大量的特征点位于背景上;第二排是这篇文章的 semantic point detector 检出的,大多数特征点集中在前景目标上。

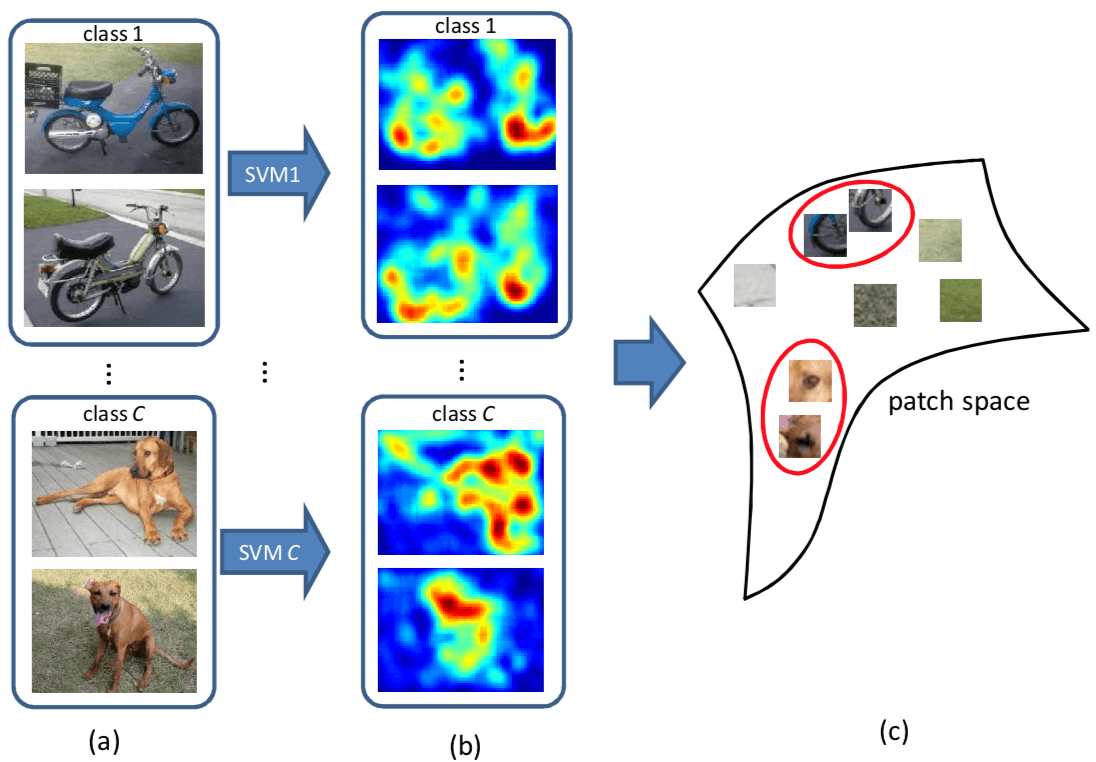
看到这里,会不由自主地产生一个疑问,单个局部的角点本身,也会具有语义吗?其实一个特征点不仅仅只是这个点本身,尤其是我们对特征点描述的时候,还包括了其周围的区域。具体到本文,与其说本文给出的是一个如其标题所说的 Semantic Point Detector,不如说实际上这篇文章做的是 Semantic Patch Detector。这篇文章具体的做法是将图像转化成 a set of 32x32 patches,步长是 4 个像素。论文中没说怎么在得到 Semantic Patch 后得到 Semantic Point,最直接的方式就是取中心点了。下图是一些 Semantic patches 的示例

既然是 Semantic Point Detector,就要有 label 来赋予 Detector 语义信息。最直接的方式当然有现成的人肉 label 好的 Semantic interest point,但这个太不现实了。这篇文章采用的是一个 Weakly Supervised Learning 的方式。对于每一个类,可以根据是否还有该类物体,构造出相应的 a set of positive images 和 a set of negative images。基于 Background Patch 会在正类和负类中都出现,而 Semantic Patch 只会在正类中出现,以此来完成对于 Semantic Patch Detector 的学习。到这里,可以发现,本文要做的问题,很类似于一个 Weakly Supervised Object Detection 问题,区别在于,Object Detection 的 Object 大小会变动,而本文只要判断固定大小的 Patch 是 Positive 还是 Negative 即可。因此,本文实际上是一个 Weakly Supervised Patch Classification 问题。弱监督则是表现在,需要预测 Patch-level 的 label,但只给了 image-level 的 label。
Weakly Supervised Learning 的核心问题就在于怎么用 Weak label 上的 loss 来改善在具体任务上的 Prediction。这篇文章是怎么建立 Weak Label 和 Accurate Prediction 之间的关系的呢,具体地说,是怎么把 image-level classification 和 patch-level classification 给联系起来的呢?本文是用了两点,第一点是 image representation 是用所有 patch representation 的 linear combination,第二点是采用了 linear SVM 作为分类器。在给定 local patch descriptor $\phi \left( I _ { p } \right)$ 的情况下,image $I$ 的 Representation 就是
$$
\Phi ( I ) = \frac { 1 } { P } \sum { p = 1 } ^ { P } \phi \left( I { p } \right)
$$
由此,图像 $I$ 在 linear SVM 下的 score $f ( I ) = w ^ { T } \Phi ( I )$ 也是所有 patch 在 linear SVM 下的 score 的 linear combination,具体如下式所示
$$
f ( I ) = w ^ { T } \Phi ( I ) = \frac { 1 } { P } \sum { p = 1 } ^ { P } w ^ { T } \phi \left( I { p } \right) = \frac { 1 } { P } \sum { p = 1 } ^ { P } f \left( I { p } \right)
$$
最后 patch-level classifier 的表示就是 $f \left( I { p } \right) = w ^ { T } \phi \left( I { p } \right)$。一言以蔽之,本文如何用 image-level classification 来指导 patch-level classification?本文的做法是,直接拿学到的 image-level classifier 作为 patch-level classifier 来使用,根本不是指导,而是自己亲下火线了。
Model
emmm… 好像 Model 上面说的差不多了,补充些细节。patch representation 用的是 Super-Vector coding,感兴趣的可以看原文的公式(1), (2), (3)。
对于 多类的情况,也很简单,相应的类别就是对应 score 最高的那个。
模型的示意图如下
Loss
Loss 就是正常的 SVM 的 hinge loss 啦,一个典型的正负类分类的 loss。
如果您觉得我的文章对您有所帮助,不妨小额捐助一下,您的鼓励是我长期坚持的动力。
 |
 |
|---|---|